使用命令及工具简介
top, linux自带,查看当前最占资源的进程jmap,jdk自带堆内存工具jstat,查看GC情况arthas,阿里开源JVM性能分析工具
状态,通常是指程序运行时的中间运算结果。
通常我们在设计微服务应用的时候,为了服务的迁移和可伸缩,通常都追求无状态, 典型的设计如tomcat的session。
默认的tomcat session会存储在服务端的内存中,由客户端保存一个sessionId进行标记。而无状态的设计大致分为两类:
利用客户端保存状态: 如JWT Token,token携带用户信息,每次交互时服务端验证解析token
利用额外存储保存状态: 如使用redis保存session, 这样tomcat就可以实现伸缩。
那么Flink的状态有什么区别,个人理解有以下区别:
首先Flink需要保存各种各样不同运算程序的中间结果,结构多种多样,并不像web应用(user,role等基本信息)那么简单,
Flink的状态可能每条数据处理都需要读取-计算-更新状态,web应用更多是读多写少的操作
如果状态采用外部存储,那么实时性、性能上都很难保证,比如每次都要读写redis;如果状态完全采用内存管理,可靠性则无法保证
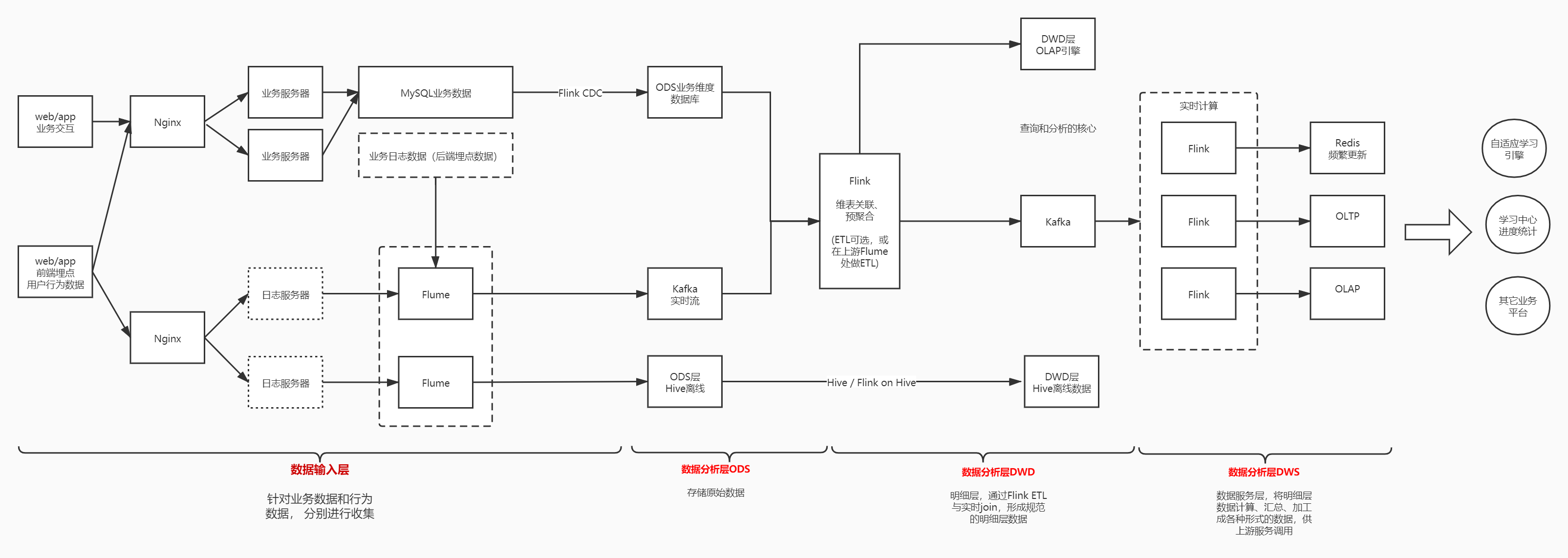
数据仓库的数据来源往往有两类:
推: 应用主动发送数据到大数据平台.
拉: 大数据平台定时从应用拉取数据.
优点:
实现简单
缺点:
耦合非常严重, 需要记录对方的访问信息和接口地址
增加业务开发人员额外工作
订阅: 应用将数据发布到消息队列, 大数据订阅主题并消费
优点:
业务与大数据解耦, 业务应用不关心谁消费了这条消息
多个消费者可以同时消费
缺点:
仍旧增加开发人员额外工作
MQ带来的复杂度, 可用性问题
离线数据同步, 适用T+1的场景 sqoop, datax
增量数据同步, canal, streamsets

窗口是另一类算子, 是DataStream的逻辑边界, 在第一个元素到达后被创建, 在生命周期结束后被销毁。
应用程序可以定义开窗机制, 触发器, 迟到生存期, 窗口聚合函数和清除器。
窗口分两大类, 即Keyed Window和 Non-Keyed Window。
滚动窗口的时间长度是固定的, 且不同时间区间的窗口不会重叠, 可根据事件时间和处理时间定义。
滑动窗口按照滑动步长将时间拆分成固定长度的窗口, 当滑动步长小于窗口长度时,相邻窗口间会重叠。
根据相邻元素之间的时间间隔确定会话窗口的边界, 分为固定时间间隔和动态时间间隔。
将相同KEY的元素聚合在一起,但是这种窗口没有起点也没有终点,因此必须自定义触发器、
拆分窗口的目的是将指定时间区间内的所有元素当成一个有界数据集, 以分析这个数据集的整体特征。
那么从实现上来看,等待所有元素都被收集后再进行计算是最简单的, 但是毫无疑问会在最后的时间里疯狂占用CPU。
如果我们采用增量式计算的设计,即数据进入引擎立刻被处理, 这样是可以提升整体计算性能。
这样的好处是让计算任务平均在每个时间点上, 不会出现某个时刻突然大量计算的问题,减轻最后的计算压力。当然也增加数据处理引擎架构设计的复杂度。
触发器原型中包括4类触发机制, 基于事件驱动。
(1)onElement: 每收到一个元素调用一次该方法。
(2)onProcessingTime: 根据注册的处理时间定时器触发。
(3)onEventTime: 根据注册的事件时间定时器触发。
(4)onMerge: 两个窗口合并时触发。
另外还提供了资源清除接口clear().
在触发器触发后, 窗口函数执行前或执行后清除窗口内元素,有以下两个方法:
1 | void evictBefore(Iterable<TimestampdValue<T>> elements, int size, W window, EvictorContext evictorContext); |
1 | void evictAfter(Iterable<TimestampdValue<T>> elements, int size, W window, EvictorContext evictorContext); |
提供了三种内置清除器: CountEvictor, DeltaEvictor, TimeEvictor
Flink默认的迟到生存期为0, 即事件时间窗口在水印到来后结束, 无需考虑事件迟到的情况。
1 | val input: DataStream[T] = ... |